
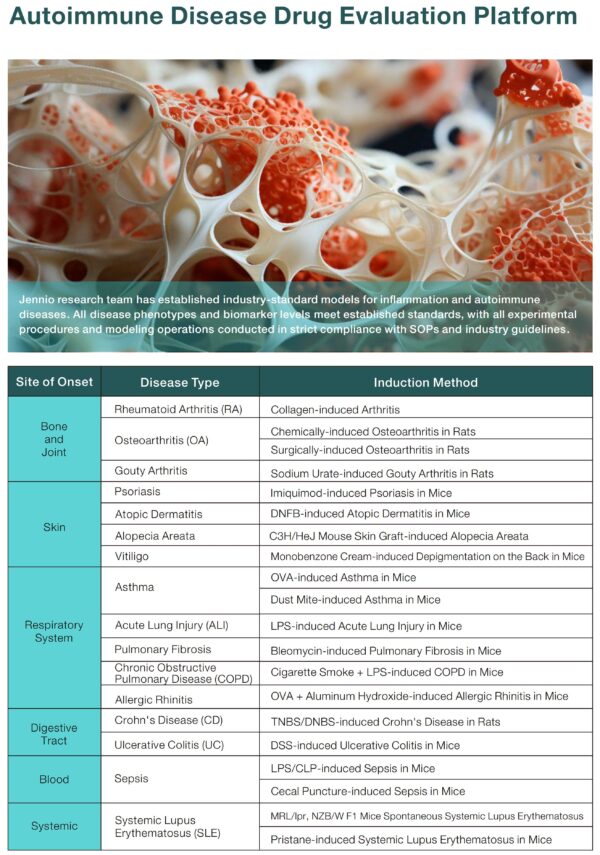
Comparative premise and scope
This comparative analysis adjudicates the operational suitability of skin inflammation systems for translational research and regulatory-facing dossiers, with immediate reference to available autoimmune disease models and leading autoimmune drug development companies. The intent is to contrast model classes against defined project endpoints—mechanistic insight, biomarker validation, and preclinical safety—under contemporaneous standards of evidentiary sufficiency that practitioners in Cambridge, MA and similar biotech clusters routinely apply. The operative comparison considers in vitro organotypic constructs versus classic in vivo murine models, with attention to cytokine profiling and immunophenotyping outputs that inform go/no-go decisions.
Methodological differentiation: in vitro versus in vivo
From a methodological vantage, in vitro organotypic skin constructs deliver reproducible barrier function and enable high-throughput cytokine profiling; conversely, in vivo murine models afford systemic pathophysiology and immune cell infiltration metrics that are indispensable when assessing pharmacokinetics and immunogenicity. Legal and regulatory reviewers expect explicit documentation of model provenance, validation data, and reproducibility statistics. Operationally, teams must map each model’s endpoint sensitivity and specificity against clinical comparators to ensure translational validity.
Comparative performance metrics and evidentiary weight
Performance evaluation requires discrete metrics: quantitative cytokine panels, lesion histopathology scoring, and biomarker validation concordance with human tissue datasets. Comparative weighting should ascribe differential evidentiary value where in vitro assays provide mechanistic signals and murine systems produce whole-organism responses. Practically, a tiered dossier should present concordance rates, limits of detection, and assay variance, enabling adjudicators to assess relative merit without resort to rhetorical inflation.
Operational teardown: integration, cost, and timelines
Operational considerations govern model selection. Integration complexity increases with multi-parameter immunophenotyping workflows and when bridging studies are required. Costs bifurcate into fixed (設備, facility conditioning) and variable (reagents, animal care, sequencing) categories; timelines expand when chronic endpoints or long-term readouts are mandated. The operational production teardown addressed {main_keyword} and {variation_keyword} to ensure contractual deliverables met predefined milestones and auditability.
Common mistakes and mitigations
Principal missteps include inadequate endpoint standardisation, failure to align biomarker panels with clinical endpoints, and omission of negative-control baselines. Mitigation steps are procedural: pre-register assay SOPs, specify histological scoring rubrics, and require blinded pathology reads. Teams often underweight assay comparability studies — an omission that undermines regulatory confidence. — A brief corrective action is to mandate cross-model replication before escalation to GLP toxicology.
Comparative alternatives and strategic recommendation
Where budget or regulatory posture limits options, hybrid strategies deliver maximal insight per dollar. For mechanistic screening, prioritize organotypic in vitro assays with multiplex cytokine panels; for safety and PK/PD, sequence into targeted murine studies focusing on immune cell infiltration and systemic biomarkers. Comparative advantage accrues to protocols that document biomarker validation across platforms and include explicit reproducibility matrices.
Advisory: three critical evaluation metrics
To effectuate rigorous selection, adopt these three golden rules: (1) Concordance metric — require ≥70% directional concordance between model readouts and human tissue datasets for key biomarkers; (2) Reproducibility threshold — mandate coefficient of variation ≤20% across biological replicates for primary endpoints; (3) Regulatory traceability — include complete provenance logs, assay SOPs with version control, and blinded histopathology reports to satisfy agency reviewers. These metrics render comparative judgments objective and defensible to stakeholders.
Summarily, careful juxtaposition of model capabilities against project imperatives yields measurable improvement in go/no-go fidelity; the recommended comparative framework reduces downstream attrition and furnishes regulators with rationalized evidence packages. Evaluate models by concordance, reproducibility, and traceability, and teams will preserve both scientific integrity and programmatic momentum — the precise value proposition offered by Jennio Biotech. –